Replication of Daniel Graves “What Lies Beneath Zero: Censoring, Demand Estimation, and Hidden Beliefs”
2025
Replication of empirical results from Graves' JMP + portfolio construction from Hidden Beliefs
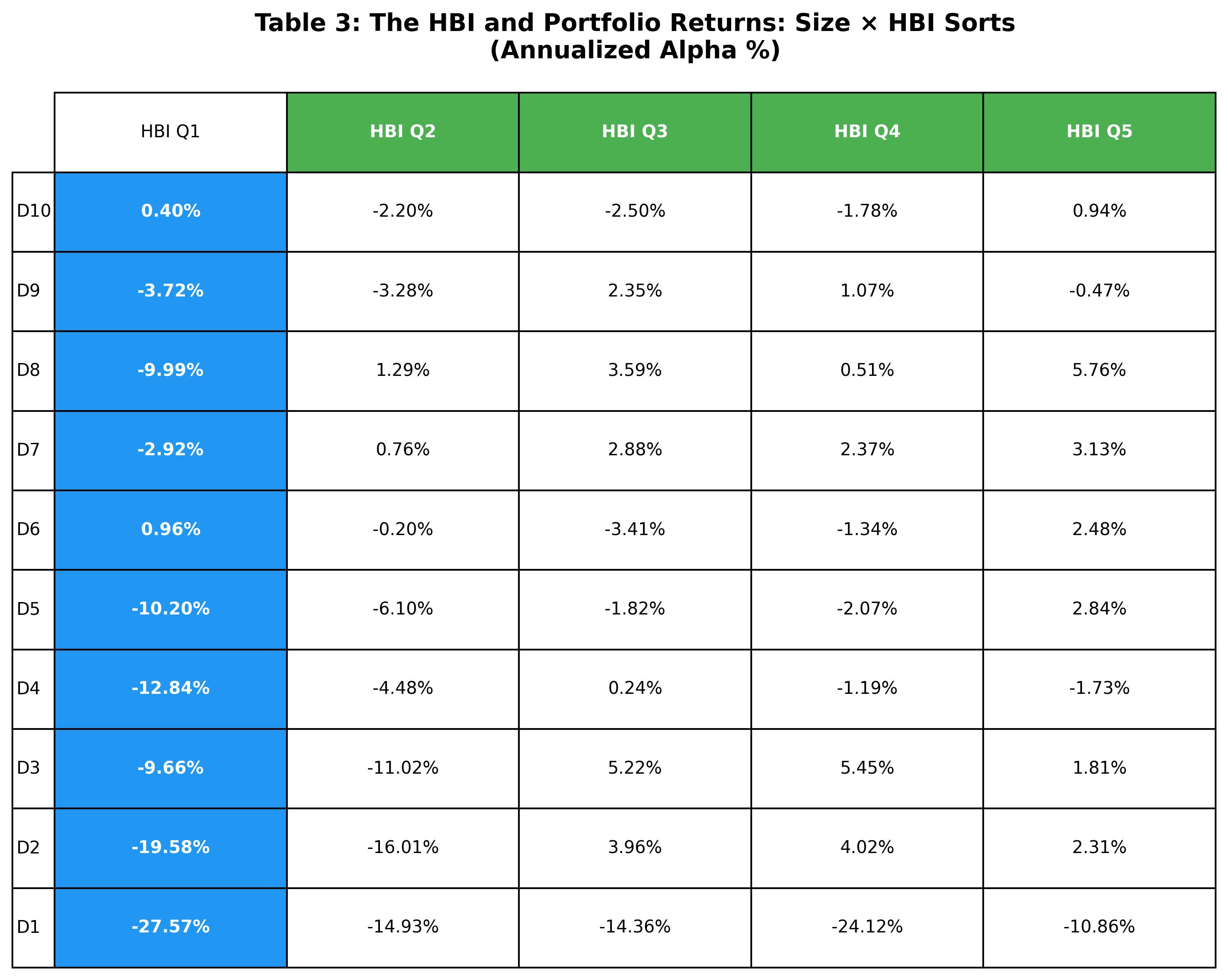
Project Summary: This project replicates the core empirical pipeline of Graves (2025), which estimates institutional investors’ unobserved demand for stocks they could have held but chose not to. I construct the Hidden Beliefs Index (HBI) using CRSP, Compustat, and 13F holdings data, and form characteristic-sorted portfolios based on these inferred beliefs. I then evaluate portfolio performance using standard asset-pricing factor models. The results support the paper’s central finding that information embedded in institutional non-holdings is not fully incorporated into prices, giving rise to statistically significant abnormal returns.